
近期,世界首个异构人形机器人训练场在上海启用,首期已部署来自智元、傅利叶、开普勒等机器人公司的超百台异构机器人,引发世界范围对于机器人训练场这种新模式的广泛讨论。

由于当前人形机器人方案路线并未统一,不同厂家的机器人,其形态、功能、技术架构、应用场景都存在差异,而且缺乏足够的训练数据,目前业界常用的做法是,人形机器人想要落地场景,就必须和企业合作开发,部署产品实际进行工序测试、验证,积累数据并优化,如果工厂换一家人形机器人企业合作,这种流程可能就需要重来。
因为机器人厂商的数据也不同,这就使得人形机器人的训练数据,往往来自不同的领域、模式和机器人硬件,很难实现统一并迁移使用。简单任务如物体特征明显的抓取或安装特定形状零件,大概需要2-3 万条数据,如果是工业上较复杂的应用,可能需要达到 10万级的数据量。例如,人形机器人在咖啡店接咖啡并递回桌面,简单动作可能1万条数据,但如果要识别多种咖啡模型,可能需要5万条数据:弯腰拿咖啡可能需要几万条数据,直拿转身可能几千条数据就够:若只是简单的抓取动作且结构识别简单,上千条数据即可。但问题在于各家厂商每次进入一个新工厂、新场景,都需要重复造轮子采集数据,这有点像是此前工业机器人集成商所做的工作。
2017年就有学者根据沃尔夫斯堡大众工厂采用不同品牌机器人的场景案例,提出异构机器人训练工厂的构想。核心思想就是,由于机器人具有不同的形态或传感器设备,异质性数据导致不同品牌的机器人训练模型不能直接重复使用,但是否可以建立一种嫁接在机器人控制系统上的架构,将来自许多来源的大量异构数据组合成一个系统,让机器人只需经过“工厂”预训练,这种迁移学习方法就能教任何机器人执行各种各样的任务,让机器人快速掌握技能并部署到产线。
机器人训练工厂的理念有点类似汽车试验场,把不同厂家的异构机器人放在同一空间运行,一方面能够测试各家人形机器人产品在动力、速度、能耗等多种性能,另一方面类似GPT-4等大型语言模型的训练方法,尝试基于异构机器人实现数据的规模化收集和生产,从而将来自不同公司产品、不同模式的数据对齐,形成生成式AI模型可以处理的共享“语言”,并建立一种基础通用技能模型,减少异构协同的幻觉,建立机器人深度学习场景技能的元标准,将机器人先置技能快速迁移复用,提升能力泛化性。
▍韩国NAVER机器人训练场
机器人集训地并不算是新鲜事物,实际难在调用大量资源。例如韩国的“谷歌”NAVER公司2022年就在京畿城南市的第二办公楼尝试打造机器人训练场,这个被命名为“1784机器人亲和建筑”的场地,旨在一个独立空间里让各类机器人运行,从而创造协同效应,并尝试融合新技术。
由于从异构数据中训练用于不同任务的通用机器人策略是一项重大挑战,整个构筑内部采用第5代(5G)移动通信特化网,以Naver Cloud环境为基础,通过云计算终端控制NAVER LABS公司的多个机器人产品,例如配送服务机器人Rookie、清洁机器人、双臂人形机器人Ambidex等,该建筑预计共使用了超过316项专利技术,有超过60个服务机器人,还有1个机器人技能训练场。

这栋大楼中融合了多个韩国财团的智慧成果。例如由三星物产建造了这座大楼,三星电子为5G系统提供了主要设备并集成。现代电梯的子公司Hyundai Movex开发了机器人专用电梯,LG Energy Solution为机器人提供电池和充电系统,Naver建构了xDM平台,并将其位于世宗的第二个数据中心用作机器人和自动驾驶技术的试验台。NAVER还是陪同韩国国土交通大臣元熙龙出访沙特阿拉伯的公司之一,韩国一直寻求参与中东国家大规模的NEOM智慧城市项目。
▍美国PI公司训练场
Physical intelligence(Pi)的第一个原型通用机器人策略π0其实就是在迄今为止最大的机器人交互数据集上进行训练的,但不用于在固定场所建立固定的数据训练模式,Pi主要与蒙特利尔大学、华盛顿大学、韩国科学技术研究院等全球近20个研究院、企业达成合作。这种松散的联盟下,虽然实验环境遍布世界各地,但Pi对其开放一部分代码库,让不同的研究院在不同的机器人系统上可以直接将π0衍生模型连接,部署并调试运行,然后进行不同的任务。
基于从互联网规模的预训练中继承了语义知识和视觉理解,Pi以较小的30亿参数VLM作为起点,而后在多个不同的机器人上收集大量多样化灵巧任务数据集,最后Pi将大规模多任务和多机器人数据收集与新的网络架构相结合,尝试将其整理成一个完整的训练组合,并在大型多样化数据集上继续训练π0。
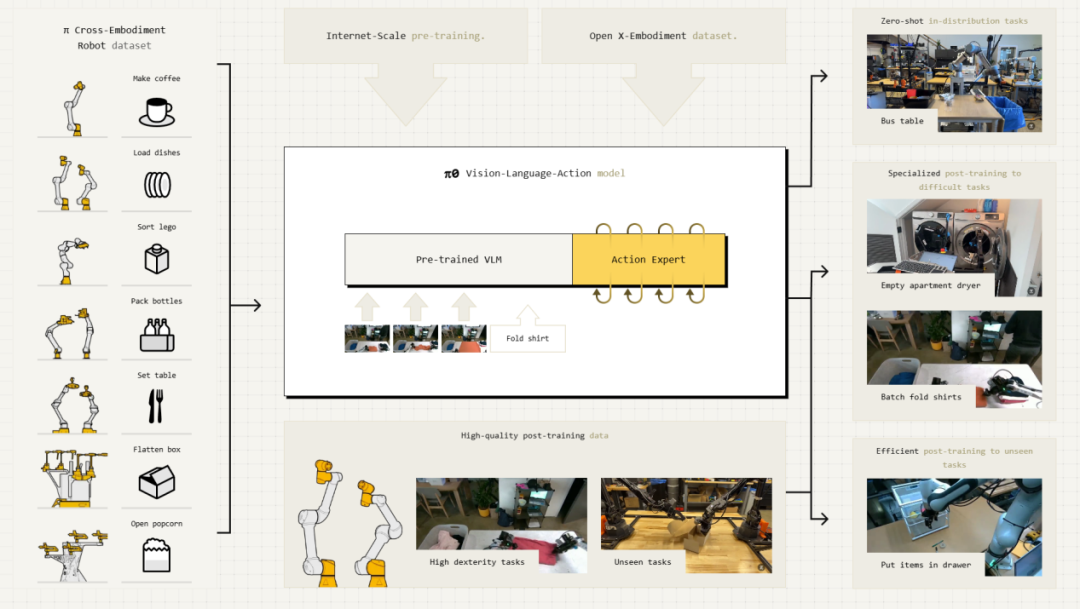
部分情况下,Pi还会发布固定挑战任务,让合作伙伴基于不同的机器人主体,对模型进行微调以完成,而后将合作伙伴的数据整合到预先训练的模型中,继续训练并提供更适用于其特定平台的模型,从而形成一种良性的循环。
Pi的这种方式证明了,企业基于互联网规模预训练的语义理解,整合来自许多不同任务和机器人平台的数据集,有望构建一种通用模型,并在机器人上实现前所未有的灵活性和物理能力,使机器人“泛化”出烧饭叠衣、装配修理、保洁照护等样样在行的复合能力。
▍特斯拉训练场
作为一个跨国科技集团,按照CEO马斯克的想法,特斯拉的整个制造工厂本质上已经成为其人形机器人Optimus的训练场,目前其已经在自有汽车和储能工厂引入一些人形机器人来执行任务并持续训练。马斯克预计,2025年Optimus将量产数千至1万台,初期Optimus会去做一些最容易应用的场景,比如为车身生产线装料、金属搬运等任务,最终实现改进循环。
此前在工厂中,Optimus的端到端神经网络经过训练,已经在部分产线上岗,例如对特斯拉工厂的电池单元进行准确分装,拾取从传送带上传递下来的电芯,并将它们精确地放入托盘中。在这个训练过程中,Optimus在机器人的FSD上以端对端的方式实时运行,直接生成关节控制序列,而后依靠2D摄像头、手部触觉和力传感器微调,并实现持续训练。

在特斯拉看来,人形机器人的第一个用例可能是在工业环境中,那里的全球正面临人力资源枯竭、成本高昂且供应不足的问题。在这些环境中,人形机器人将得到磨炼和优化,同时还能完成生产性工作,创造收入或削减成本。同样,这是特斯拉比竞争对手拥有巨大优势的领域。特斯拉拥有多家非常大的工厂,可以在这些工厂部署 Optimus,而无需与外部合作伙伴达成复杂的协议。
特斯拉也有自己的人类数据收集农场,其招募了数十名员工,利用动作捕捉技术帮助训练其人形机器人Optimus。特斯拉为这项工作提供了三个不同的班次:早上8点到下午4点30分、下午4点到凌晨12点30分,以及凌晨12点到早上8点30分。工作者需要每天行走超过七个小时,同时携带重达30磅的货物,并长时间佩戴VR头盔。职责包括上传收集的数据、根据观察起草报告以及偶尔解决问题。特斯拉是全球首批如此大规模地并在广泛的通用任务中实施动捕技术的企业。
因为特斯拉的Optimus机器人是全新定制和组装集成的新产品,这种自研自产机器人并在自家工厂作业训练优化的方式也有诸多优势,例如能够随着公司不断改进和完善技术,Optimus人形机器人的每个单元都能更快迭代,并验证软硬件可靠性以及快速落地。
▍国地中心人形机器人训练场
中国的人形机器人训练场由国家地方共建人形机器人创新中心搭建,占地面积约5000平方米,首次对人形机器人大数据、大智算、大实训场、大模型进行一体化规划,通过与海尔、海信、康佳、延锋汽车等下游应用企业合作构建了冰箱、电视、汽车装配等训练科目场景,并通过遥操作+动捕等4种不同数据采集手段,旨在弥合机器人协作任务中自然语言命令和物理基础之间的差距,快速通过人形机器人收集大量高质量数据,构建规模领先的异构具身智能数据集,持续训练和优化算法,形成更有效的基础通用模型。
国地中心人形机器人训练场能实现单台机器人每日采集轨迹数据500条以上,受训机器人能够完成涉及桌面整理、物品分拣、设备操作在内的多类型任务,平均执行成功率达到90%以上,今年有望沉淀下1000万条数据,从而形成业内规模领先的异构人形机器人数据集,成为支撑机器人基础模型进化的高质量语料,最终解决数据缺乏统一标准和规范、无法跨平台跨行业迁移和复用等问题。

据悉,训练场一期建设重点围绕四大目标展开:一是构建可重构场景和异构机器人,涵盖智能制造、民生服务和特种应用三大领域的超过10个场景,可迁移的超100款异构人形机器人集合;二是搭建异构集群采训推开源框架,推出国内领先的真实与生成式动作开源数据集,训练通用技能模型,形成通用技能库和知识迁移部署能力;三是具身智能操作及任务调度,发布完整的“智能操作系统-技能库-任务编排”应用系统,完成“人形数据管控平台-5G通信基础设施平台”建设,在数据网联方面完成可靠稳定的“传输-显示-调度”工作;四是开源共享和贡献机制,基于训练场打造OpenLoong四级开源会员模式,推动训练数据集的开源共享,并与全球实验室和企业合作,共同促进人形机器人技术创新发展。
人形机器人是真正的大国工程,其产业链更长,人形机器人训练基地的构建无疑难度颇高,需要人才和资源的高度集中。国地中心人形机器人训练场代表了一种人形机器人数据采集的规模效应和独特发展模式,有望加快中国人形机器人行业走向大规模量产与应用之路。预计今年年中,国地中心将发布人形机器人通用数据集、标准体系和重点应用等成果,并面向高校、实验室等推动部分训练数据集的开源共享。



