
正在德国举办的机器人研究领域的顶级学术会议CoRL 2024,清华大学交叉信息研究院高阳研究组发布重磅研究成果,提出“基于大模型先验知识的强化学习”框架(Reinforcement Learning with Foundation Priors) 来促进具身智能体在操作任务中的学习效率和自主探索能力。该框架通过利用策略、价值和成功奖励等基础模型为智能体提供指导和反馈,成功地使机器人能够在真实环境和仿真环境中更高效地完成复杂的操作任务。
▍现有强化学习方法当中两项棘手问题尚未解决
强化学习(Reinforcement Learning, RL)作为一种有效的机器学习方法,近年来在多个领域取得了显著成就,尤其是在游戏AI和模拟机器人任务中。然而,将强化学习算法直接应用于现实世界的机器人操作中依然面临很多短板,包括样本效率低和奖励函数设计复杂等。针对这些问题,清华大学高阳研究组提出“利用基础先验知识的强化学习框架”通过结合策略、价值和成功奖励等基础先验知识,提高强化学习的效率和自主性。
样本和函数复杂是制约强化学习在机器人交互当中的主要影响因素,在样本的获取方面,强化学习通常需要数百万次与环境的交互才能学会解决复杂任务,这在现实世界中是不切实际的。而奖励函数则需要开发者精心设计,从而引导智能体学习期望的行为,这需要耗费大量的时间和精力成本。
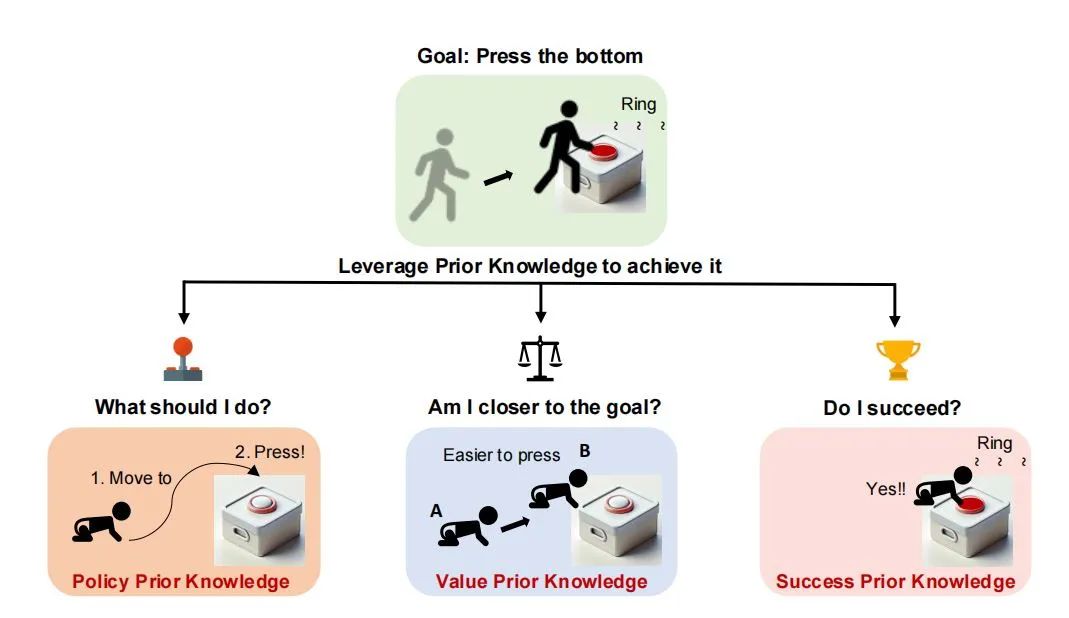
人类在策略、价值和成功奖励先验知识下如何解决问题
这些问题限制了强化学习在真实机器人操作中的应用。而人类则完全不同,人类可以通过利用先天能力和日常生活中的常识积累,在与环境的少量交互中快速学习新技能。那么机器人是否可以结合先验知识来提高强化学习的效率和自主性呢?
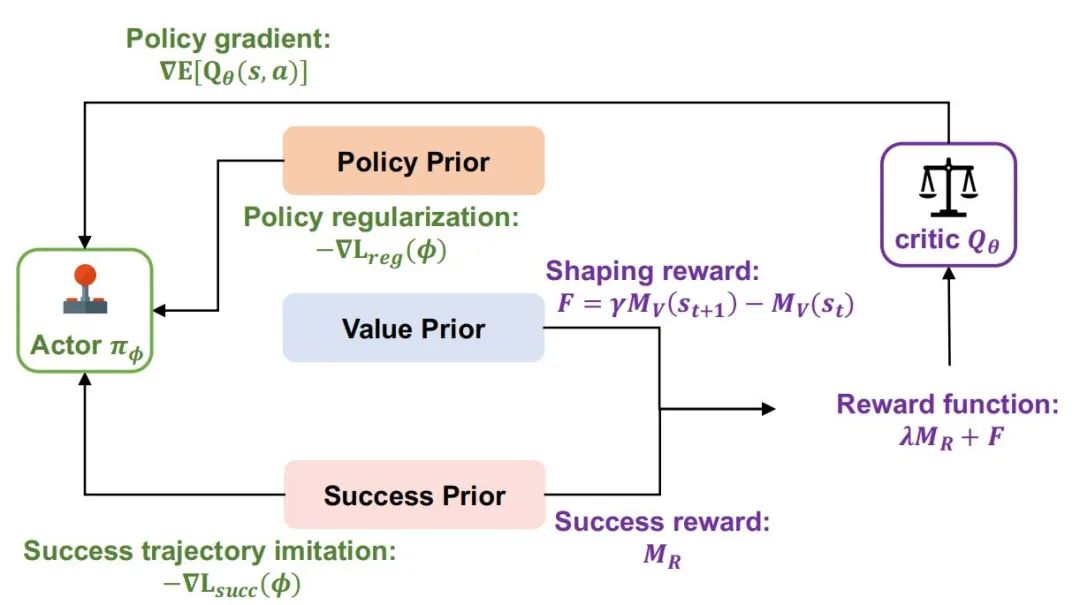
基于基础模型引导的Actor-Critic方法概述
RLFP框架的提出解决了这个问题,该框架通过利用策略、价值和成功奖励等基础先验知识,指导智能体在强化学习过程中的探索和学习。这些先验知识分别对应强化学习中的策略函数、价值函数和成功奖励函数,为智能体提供了关于“现在应该做什么”“我是否更接近目标”以及“我是否成功”的反馈。
RLFP框架包含以下几个关键部分:
策略先验知识:为智能体提供一个初始行为指导,帮助智能体从合理的起点开始探索。
价值先验知识:提供关于状态好坏的估计,指导智能体向更有利的状态转移。
成功奖励先验知识:给出任务是否成功的最终反馈,用于强化成功的尝试并避免不成功的行为。
通过结合这些先验知识,RLFP框架能够提升强化学习的样本效率,减少对人类设计的奖励函数的依赖,同时对先验知识的形式具有一定的鲁棒性。
▍基于RLFP框架的FAC算法引导智能体完成高效的自主学习
在RLFP框架的基础上,高阳研究组又提出了一个FAC(Foundation-guided Actor-Critic)算法,该算法将策略、价值和成功奖励先验知识有效融合,以指导智能体的学习过程。在算法实现上,FAC首先构建了两个核心网络:演员网络和评论家网络。演员网络负责根据当前状态生成动作,其参数通过梯度上升法进行优化,以最大化长期回报。而评论家网络则评估演员网络所采取动作的价值,为演员网络提供反馈,帮助其调整策略。
为了实现高效的自主学习,FAC算法引入了成功缓冲区,存储被成功奖励先验知识识别的“成功”轨迹。在每次更新演员网络时,算法不仅考虑当前的策略梯度,还会从成功缓冲区中采样,模仿这些成功的轨迹。这种模仿学习机制使得智能体能够快速吸收成功的经验,加速学习进程。
同时,FAC算法还利用价值先验知识对评论家网络进行塑形,以指导探索过程。通过潜在函数塑形奖励,算法能够在不改变最优解的前提下,引导智能体避开不理想的状态,提高学习效率。此外,策略正则化引导也作为算法的一部分,通过策略先验知识对演员网络进行约束,鼓励智能体在探索过程中保持合理的行为范围,避免偏离正确路径。
▍实验与结果分析
在真实机器人实验中,研究人员使用了一个具有7自由度手臂和1自由度平行夹爪的Franka Emika Panda机器人,并设计了五个灵巧操作任务:拾取放置、开门、浇水、拧瓶盖和高尔夫击球。

在真实机器人上进行的五项任务 展示了FAC在实际应用中的效率和准确性
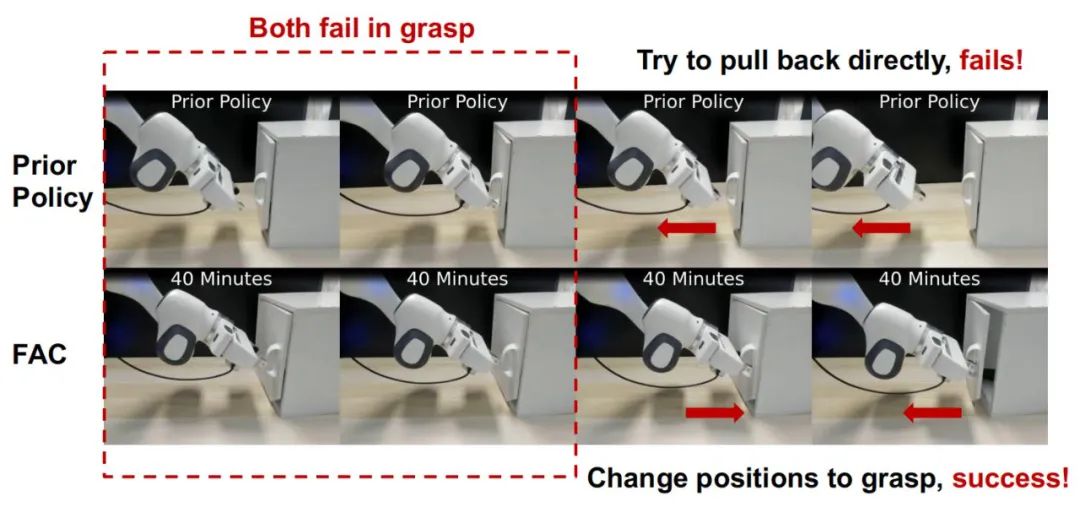
先验策略试图在没有成功抓住的情况下打开门,而FAC则持续尝试在拉回手臂之前稳固地握住把手。
实验结果表明,经过一个小时的实时学习,FAC算法在五个任务上的平均成功率达到了86%,明显优于仅使用手动设计奖励的强化学习基线方法和基于GPT-4V生成代码策略的方法。
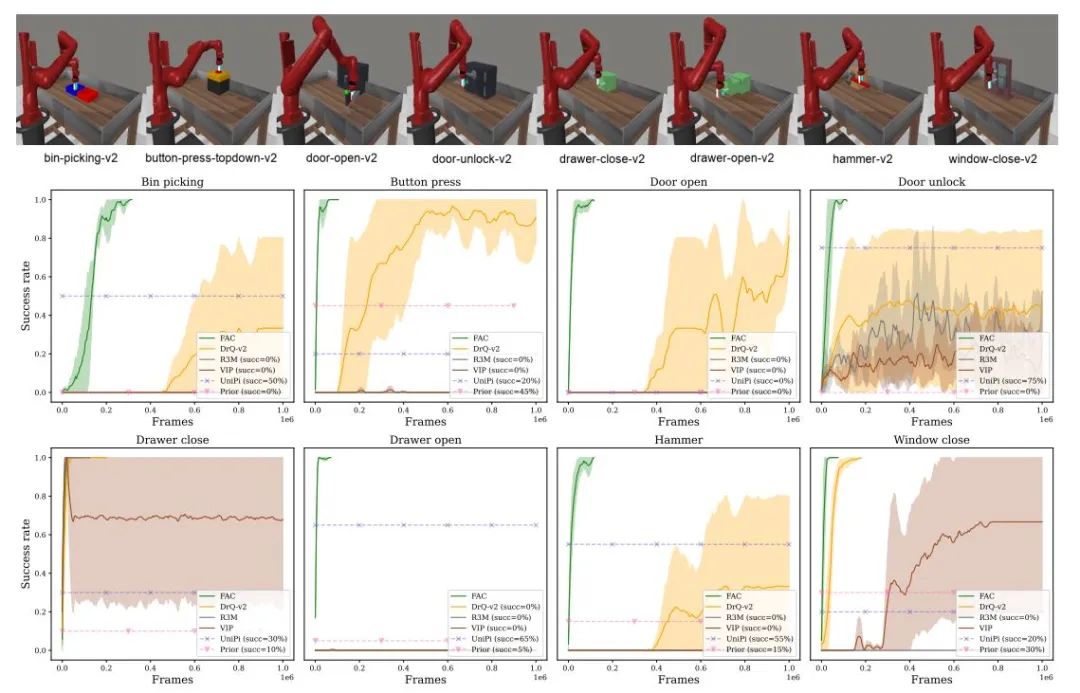
Meta-World中8项任务的成功率曲线
在模拟实验中,研究人员在Meta-World环境中测试了FAC算法在八个任务上的表现。实验结果显示,FAC算法在七个任务上实现了100%的成功率,且训练时间不超过100k帧(约一小时)。相比之下,基线方法即使在1M帧的训练后也无法在所有任务上达到100%的成功率。
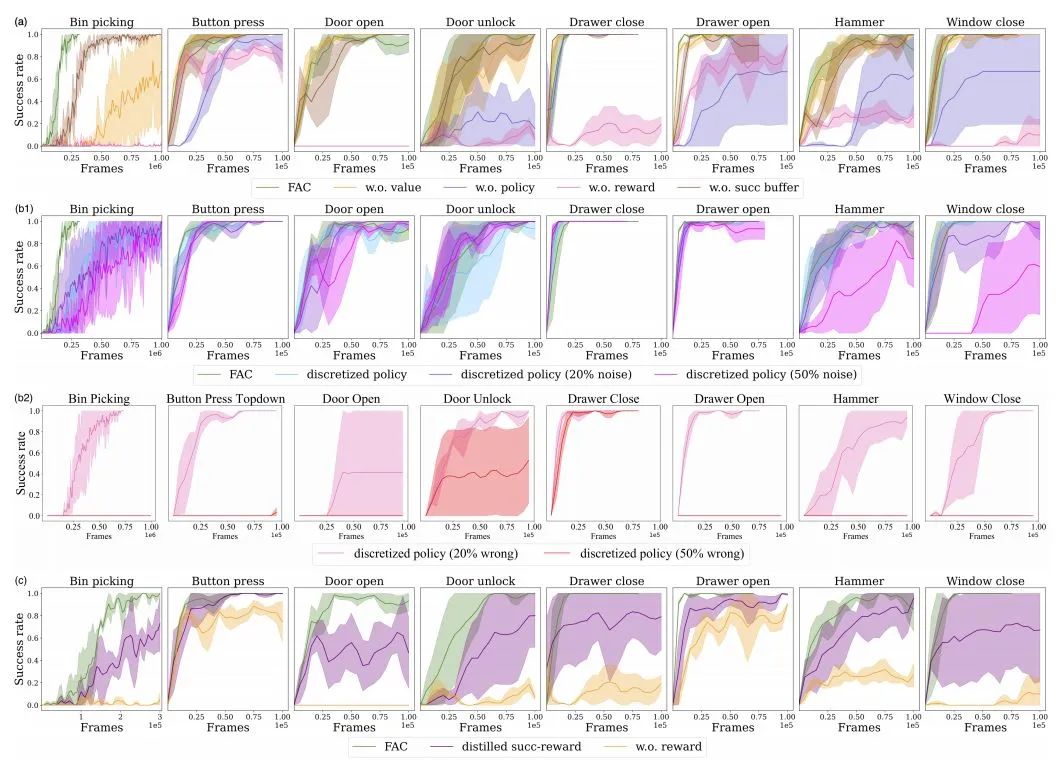
消融实验结果
通过消融实验,研究人员进一步分析了策略、价值和成功奖励先验知识对FAC算法性能的影响。实验结果表明,成功奖励先验知识对性能的影响最大,而策略和价值先验知识则在不同程度上提高了样本效率和成功率。此外,FAC算法还对先验知识的质量具有一定的鲁棒性,即使在先验知识存在噪声的情况下仍能保持较好的性能。
▍基于RLFP框架和FAC算法的一些思考:
RLFP框架和FAC算法为强化学习在现实世界中的应用提供了新的思路和方法。通过结合策略、价值和成功奖励先验知识,RLFP框架显著提高了强化学习的样本效率和自主性,减少了对人类设计的奖励函数的依赖。同时FAC算法有望在更多复杂任务中发挥作用,特别是在那些奖励函数难以明确定义或环境动态变化的场景下。
不过研究人员也表示,当前RLFP框架仍依赖于人类工程来设计低层次技能和提示,并未真正完成自主生成的技能,此外,当前实验中使用的先验知识主要来自预训练的模型,并未打通网络端,在线获取或更新更加先进的知识。同时人类除了策略、价值和成功奖励先验知识外,还具有其他形式的先验知识,如预测未来状态的能力。这些都是未来RLFP框架需要持续迭代并解决的方向。
关于第一作者:

叶伟睿清华大学交叉信息研究院(IIIS) 2017级博士研究生,导师为高阳教授,此前在清华大学软件学院获得学士学位,于龙明生教授和徐峰教授的指导下进行研究。研究方向是开发视觉感知下的具身智能体的人类级策略学习算法。个人兴趣点聚焦基于模型的强化学习、决策的基础模型、机器人学习等。
来源:微信公众号具身智能大讲堂



