
在自然语言处理与计算机视觉领域,高容量模型基于开放的不可知的任务训练,可以吸收大规模数据集中呈现的知识,从而学习到通用能力。然后,该模型可以在特定的新任务实现少样本或零样本泛化的能力。这种通用能力在机器人领域更为重要。虽然近几年产生了许多大的多任务的机器人策略,但是它们的泛化能力很差。这是因为存在两大挑战,分别是:
· 构造合适的数据集
· 设计合适的模型
2022年 Google 机器人研究团队历时17个月基于13个机器人得到了 130k episodes 以及超过700个任务的数据,这些数据可以使机器人能够形成很好的泛化能力,从而使机器人能够发现结构相似任务之间的模式,且应用到新任务上。该数据集不仅仅规模很大,而且广度很大。在该数据集的基础之上,基于模仿学习中行为克隆学习范式,把 Transformer 应用机器人的操纵任务上,提出了 RT-1模型。
2023年 Google 的 DeepMind 团队基于互联网上数据训练视觉-语言模型(VLM),使其能够学习到更多关于视觉和语 言之间映射关系的知识后,在机器人操纵任务上微调,提出了 RT-2 。接下来,分别对 RT-1 与 RT-2 介绍。
▍RT-1
高效的机器人多任务学习需要高容量模型。虽然 Transformer 在自然语言处理与计算机视觉领域展现出惊人的性能,但是它无法高效的实时运行。因此,作者们提出了一个机器人Transformer ,被称为RT-1,它可以把相机图片、指令与电动机命令作为输入,即可对高维的输入与输出进行编码。RT-1 的架构、数据集、以及评估概览,可见图1所示。
最终,实验表明 RT-1 可以展示较强的泛化能力和鲁棒性,可见图1.b,且可以执行长期任务。

图1 RT-1架构、数据集以及评估概览
▍概览
用于RT-1 研究的机器人有7个自由度的机械臂、两个手指型夹抓,以及一个移动基座,可见图2(d)所示。为了收集数据和训练模型,构建了一个仿真环境,可见图2(a)所示。两个真实厨房环境用于评估,可见图2(b,c)。真实厨房与仿真环境中厨房拥有相似的柜台,只是灯光、背景、以及厨房的几何结构不同。训练数据由人类提供的演示组成,并根据机器人执行的指令对每个 episode 进行文本注释。

图2: (a)大规模收集数据的机器人工作室;(b)用于评估的真实办公室厨房Kitchen1;(c)用于评估的真实厨房Kitchen2; (d)移动的操纵者;(e)用于扩展技能多样性的被操纵对象;(f)扩展Picking技能的对象
该系统主要的贡献:RT-1 是一个高效的模型,可以吸收大量的数据,可高效的泛化,且可实时对机器人进行控制。RT-1 的输入由图片序列、自然语言指令构成,输出由机械臂运动的目标位姿( Toll , pitch gaw , gripper stαtus)、基座的运动 、模式转换指令构成。机器人有三个模式,分别是:控制机械臂、基座、或者终止。
▍模型
RT-1 的模型架构可见图3所示。接下来,自上而下的详细介绍模型架构。
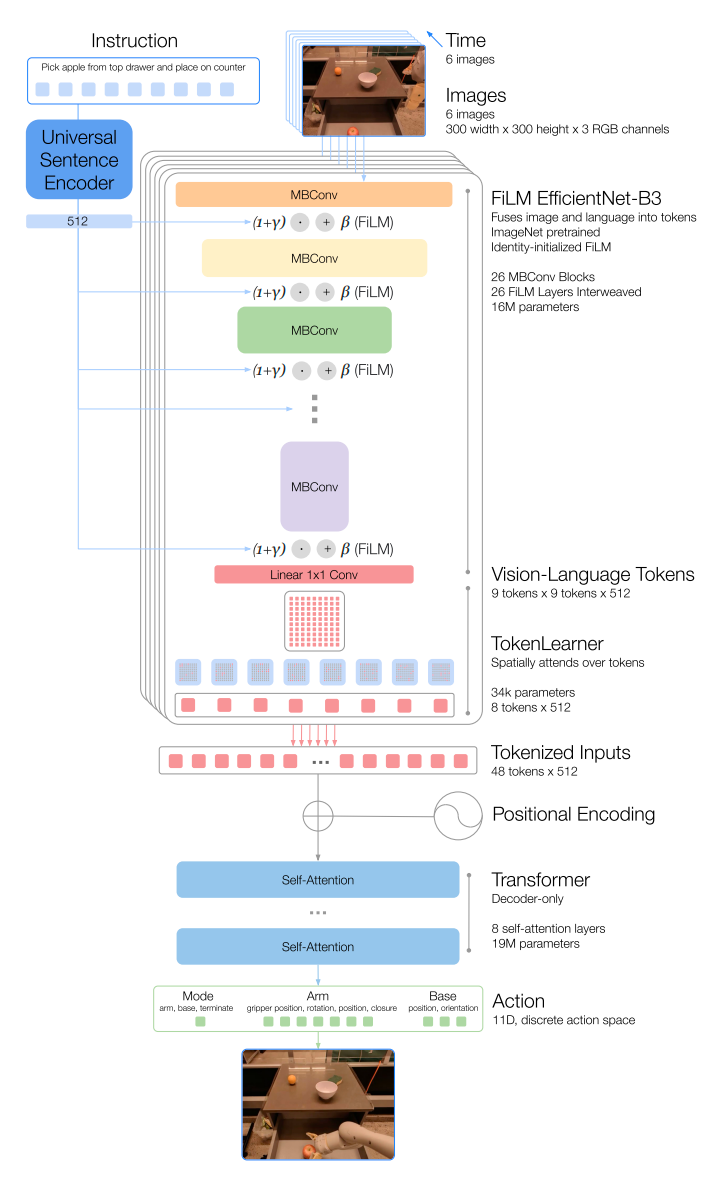
图3 RT-1架构
▍Instruction and image tokenization
RT-1 中 EfficientNet-B3 把过去的6张图片进行 tokenization 。6张的图片作为输入,输出的 特征地图,再被打平为维的视觉 tokens 。其中,EfficientNet-B3 的权重是基于ImageNet 预训练权重初始化的。
为了包含语言指令,以预训练语言 embedding 的形式调整图片 tokenizer ,允许抽取任务相关的图片特征,从而提升表现。首先,语言指令通过 Universal Sentence 编码器编码。然后,该 embedding 被用于输入到恒等初始化的 FiLM 层。紧接着, FiLM 层被添加到预训练 EfficientNet 以调节图片编码。由于把 FiLM 直接嵌入到预训练网络会扰乱中间激活函数,从而抵消掉预训练权重的效果。为了克服该问题,初始化FiLM层为恒等形式,从而保护预训练权重。
▍TokenLearner
为了进一步压缩 tokens 的数据,从而加速推理, RT-1 使用了 TokenLearner 。TokenLearner是一个元素级别的注意力模块,可以学习大量 tokens 到更少量 tokens 之间的映射。最终,把每张图片81维的视觉 tokens 变为8维的 tokens , 6张图片 concat 到一起,共48维 tokens 输入到Transformer 的 Decorder 架构。
▍Action tokenization
为了 tokenize actions , RT-1中每个动作维度通过均匀采样的方式被离散化为256个桶。这种离散化技术应该是 Sequential DQN 中的建模方式。
▍Loss
损失函数为标准的交叉熵损失函数和因果掩码。
▍Inference speed
为了能够使机器人的执行速度类似于人,希望机器人执行任务至少的控制频率。因此,利用了如下技术加速推理:
· 通过利用 TokenLearner 减少预训练 EfficientNet 生成 tokens 的数量。
· 计算 tokens 之后存储下来,减少重复计算。
▍RT-2
与 RT-1 关注模型的泛化能力相比, RT-2 的目标是训练一个学习机器人观测到动作的端到端模型,且能够利用大规模预训练视觉语言模型的益处。最终,提出了一个在机器人轨迹数据和互联网级别的视觉语言任务联合微调视觉语言模型的学习方式。这类学习方法产生的模型被称为 vision-language-action(VLA) 模型。经过评估,发现该类模型获得了涌现能力,包括泛化到新对象的能力、解释命令的能力、根据用户指令思维推理的能力。如图1所示, RT-2 模型概览。
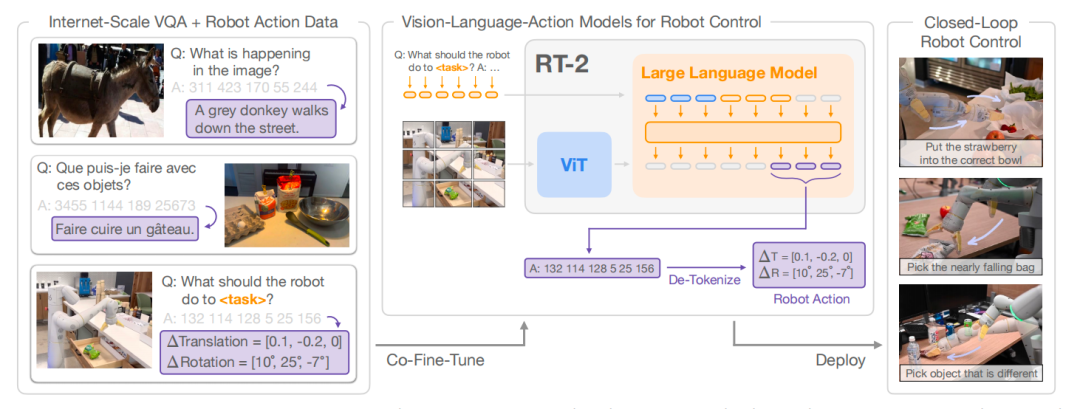
图4 RT-2概览
简单来说, RT-1 是利用预训练模型对视觉与语言进行编码,然后再通过解码器输出动作。与之不同, RT-2 把语言、动作、图片放在一个统一的输出空间,利用 VLMs 产生语言,也可以理解为“动作”为特殊的语言。总的来说, RT-2 分 为两步:首先对 VLMs 在大规模互联网数据进行预训练,然后在机器人任务上微调。
▍视觉-语言-动作模型
▍视觉-语言模型预训练
RT-2基于PaLM-E和PaLI-X视觉语言模型在视觉解释和推理任务上预训练。预训练任务从根据语言创作图到单个对 象与其它对象之间关系问题的回答。
▍机器人-动作微调
RT-2 直接把动作tokens当作语言tokens,把 RT-2-PaLI-X 模型和 RT-2-PaLM-E 模型在机器人控制任务上微调。与 RT- 1 一样,末端执行器的目标位姿作为动作空间,每一维度的动作空间被均匀的离散化为256个桶。
输出动作一种可能的方式是输出一个数字字符串,例如“1 128 91 241 5 101 127”。对于PaLI-X ,拥有1000个独立 的 token ,因此可以直接利用这些 token 与动作离散化的桶相关联,用微调模型;对于 PaLM-E ,由于没有给出独立的 tokens ,因此需要覆盖之前学习过的256个 tokens ,这种微调方式为符号微调。
值得注意的一个技术细节是联合微调, RT-2在互联网数据和机器人控制数据上联合微调。这种方式使模型能够学到 更多任务之外的语言或图像知识。同时,为了保证模型在机器人控制任务上输出有效的动作,因此对输出进行了限制。
▍实时推理
为了能够实时控制机器人,把模型部署在云服务上,机器人通过服务请求的方式获取控制指令。
----------------END-------------------

工业机器人企业
埃斯顿自动化 | 埃夫特机器人 | 节卡机器人 | 珞石机器人 | 法奥机器人 | 非夕科技 | CGXi长广溪智造 | 大族机器人 | 越疆机器人 | 睿尔曼智能 | 优艾智合机器人 | 阿童木机器人 | 盈连科技
服务与特种机器人企业
医疗机器人企业
元化智能 | 天智航 | 思哲睿智能医疗 | 精锋医疗 | 佗道医疗 | 真易达 | 术锐®️机器人 | 罗森博特 | 磅客策 | 柏惠维康
人形机器人企业
优必选科技 | 宇树 | 达闼机器人 | 云深处 | 理工华汇 | 傅利叶智能 | 逐际动力 | 乐聚机器人 | 星动纪元
核心零部件企业
绿的谐波 | 因时机器人 | 脉塔智能 | 伟景智能 | 锐驰智光 | 地平线 | 本末科技 | NOKOV度量科技 | 青瞳视觉 | 因克斯 | 蓝点触控
教育机器人企业
硅步机器人 | 大象机器人 | 中科深谷 | 史河科教机器人
加入社群
欢迎加入【机器人大讲堂】读者讨论群, 共同探讨机器人相关领域话题,共享前沿科技及产业动态。
教育机器人、医疗机器人、腿足机器人、工业机器人、服务机器人、特种机器人、无人机、软体机器人等专业讨论群正在招募, 添加微信“robospeak2018”入群!
兼职作者&投稿
机器人大讲堂正在招募【兼职内容创作者】,如果您对撰写机器人【科技类】或【产业类】文章感兴趣,可将简历和原创作品投至邮箱:liuzk@leaderobot.com
我们对职业、所在地等没有要求,欢迎朋友们的加入!


看累了吗?戳一下“在看”支持我们吧



